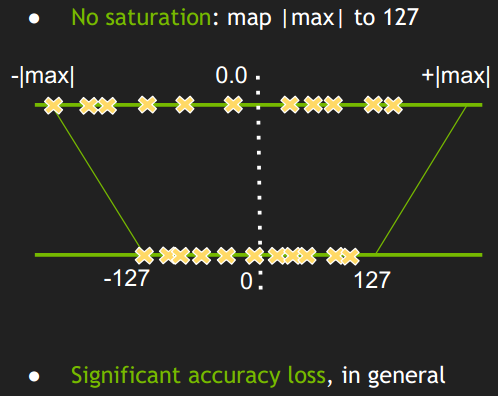
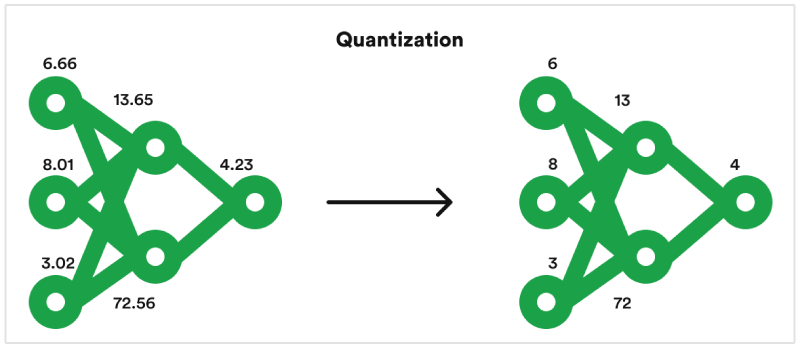
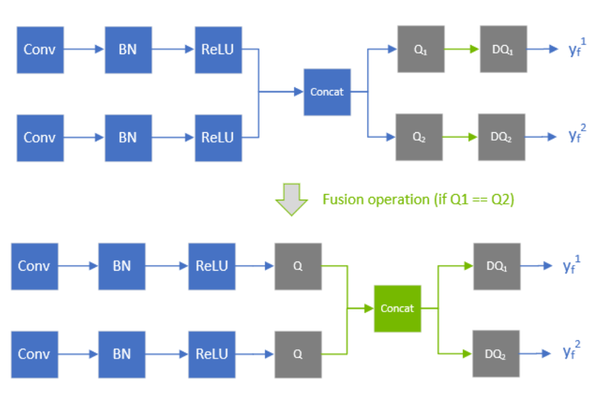
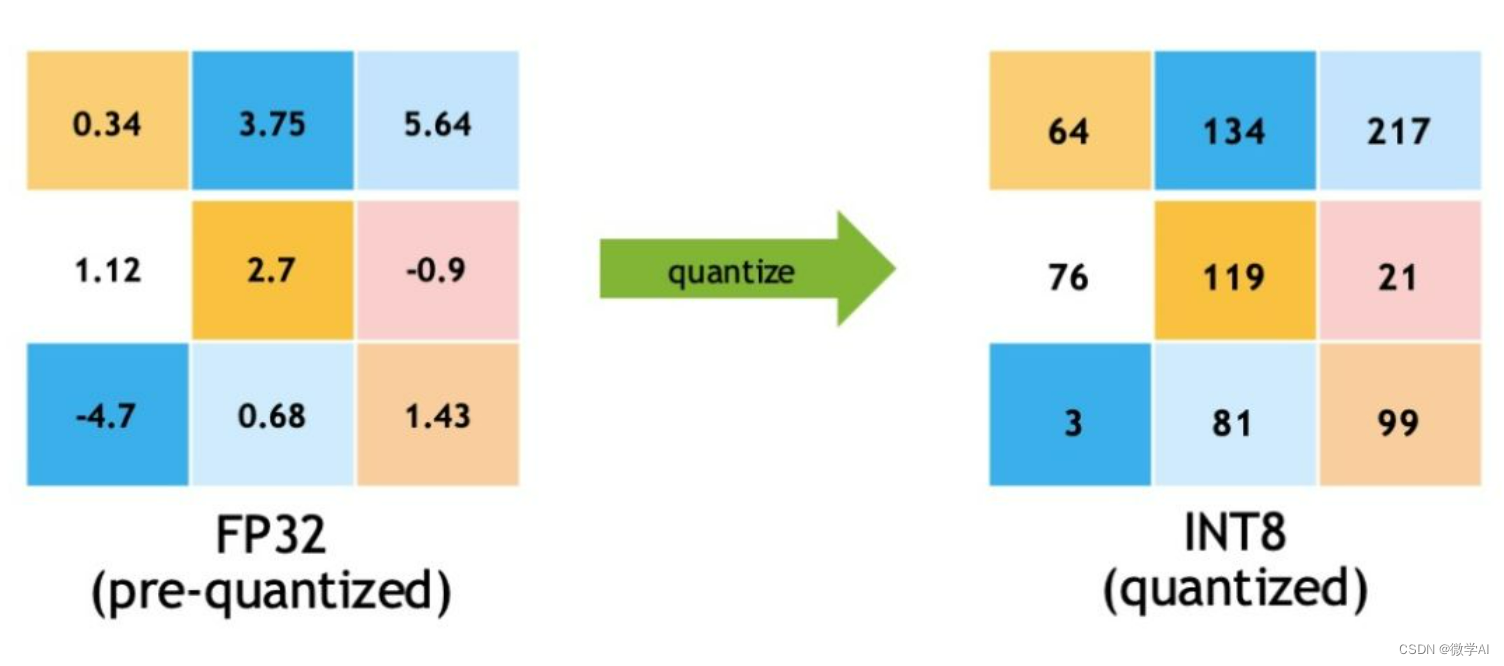
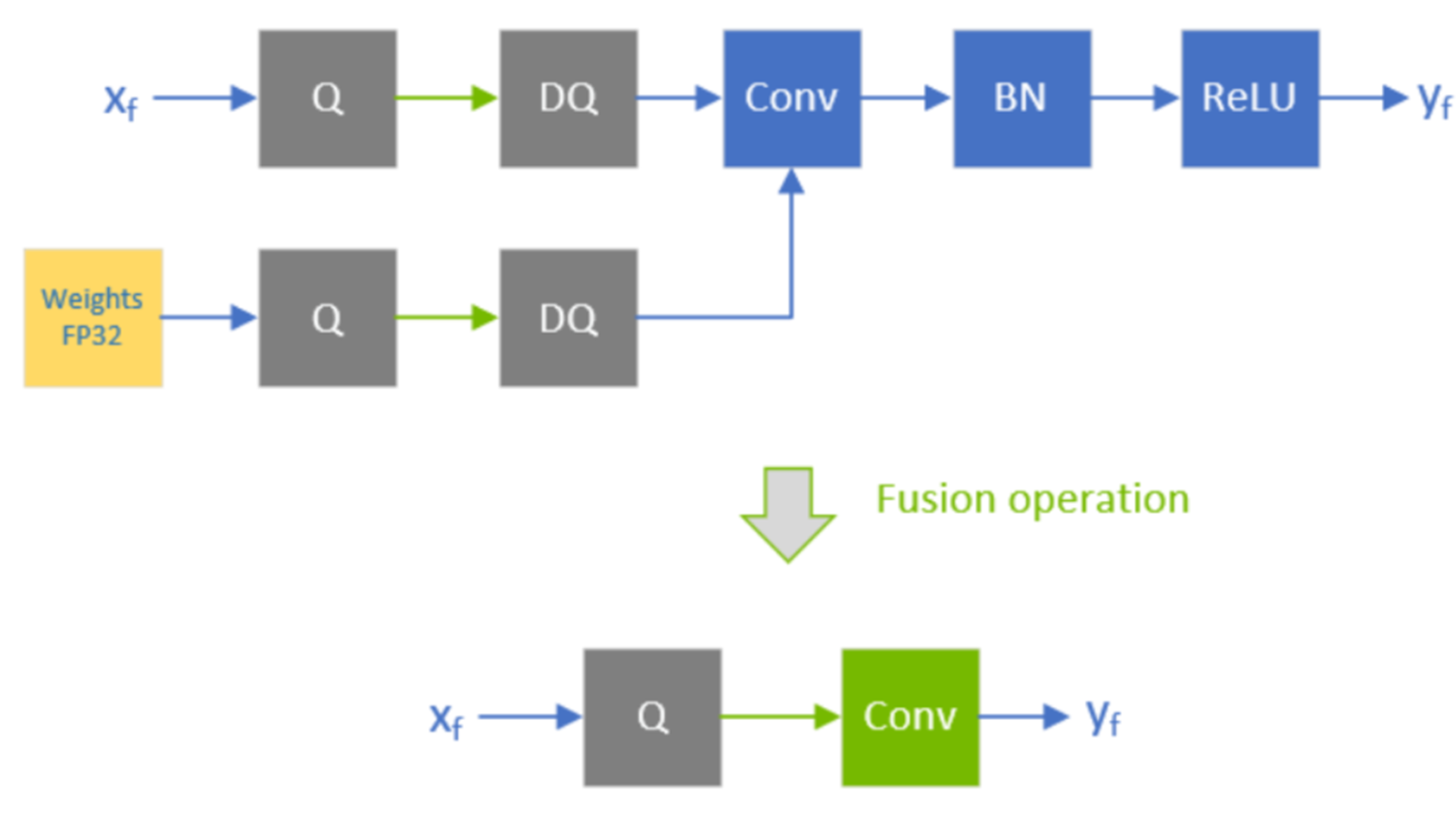
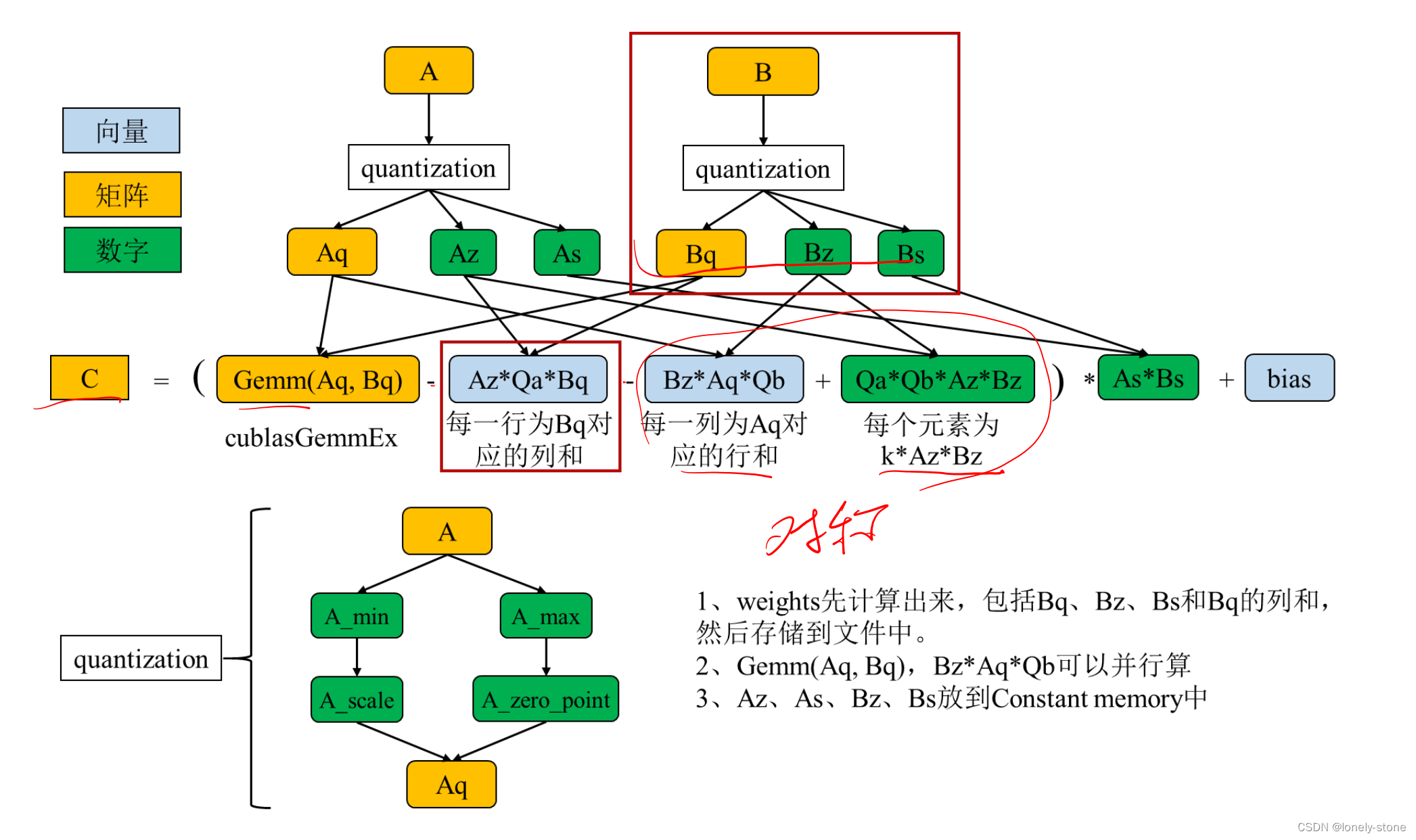
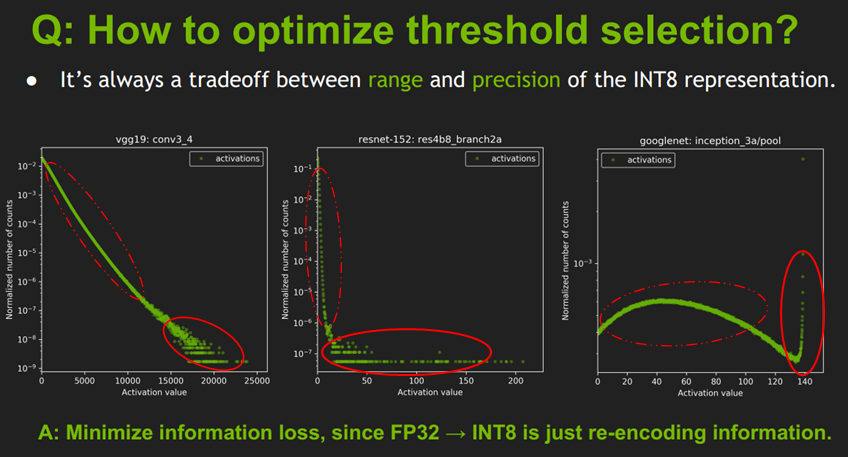
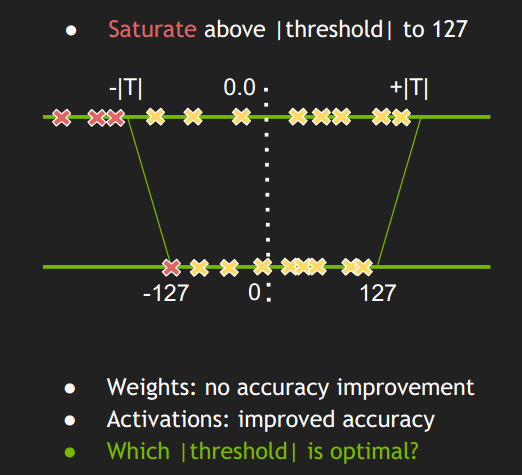
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
TensorRT INT8 quantization principle and how to write a calibrator ...
INT8 Quantization of dinov2 TensorRT Model is Not Faster than FP16 ...
NVIDIA TensorRT INT8 & FP8 quantization accelerating SD inference : r ...
Cannot export models to TensorRT with int8 quantization · Issue #82463 ...
Does TensorRT support QAT & PTQ INT8 quantization of clip/vit models ...
INT8 quantization under TensorRT for yolov5 · Issue #304 · wang-xinyu ...
Quantization to int8 still confusing - TensorRT - NVIDIA Developer Forums
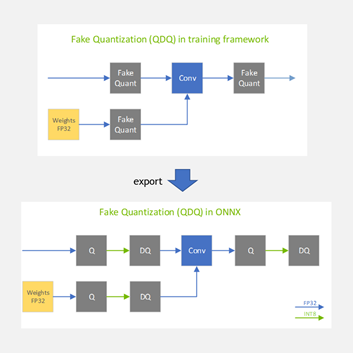
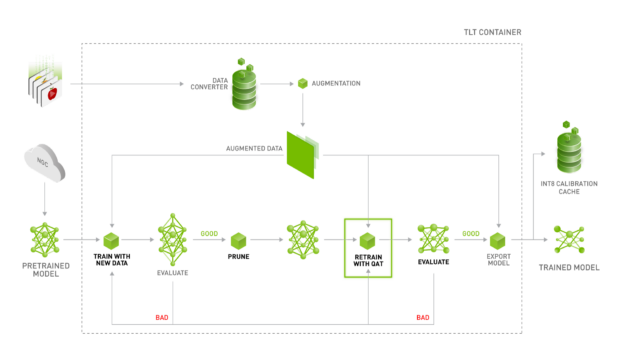
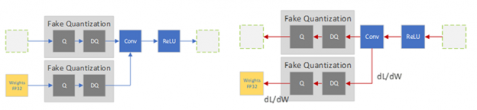
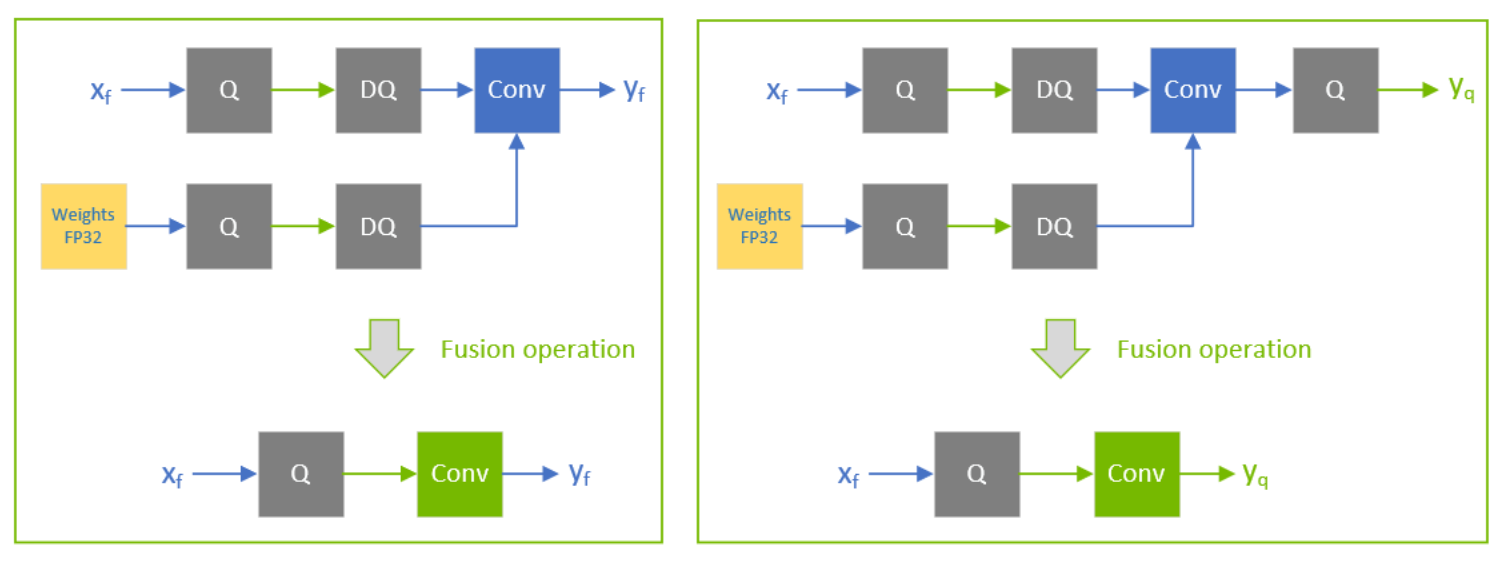
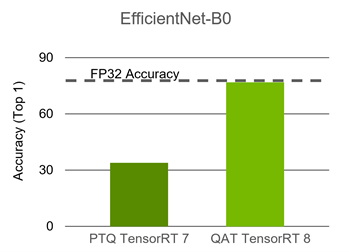
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
利用 NVIDIA TensorRT 量化感知训练实现 INT8 推理的 FP32 精度 - 广州市迈进信息科技有限公司/研云创服务器
Deploying Quantization Aware Trained Models In Int8 Using Torch ...
INT8 quantization with same model and different weights · Issue #2705 ...
how to convert a static quantized onnx model to tensorrt int8 engine ...
INT8 KV cache + per-channel weight-only quantization leading to wired ...
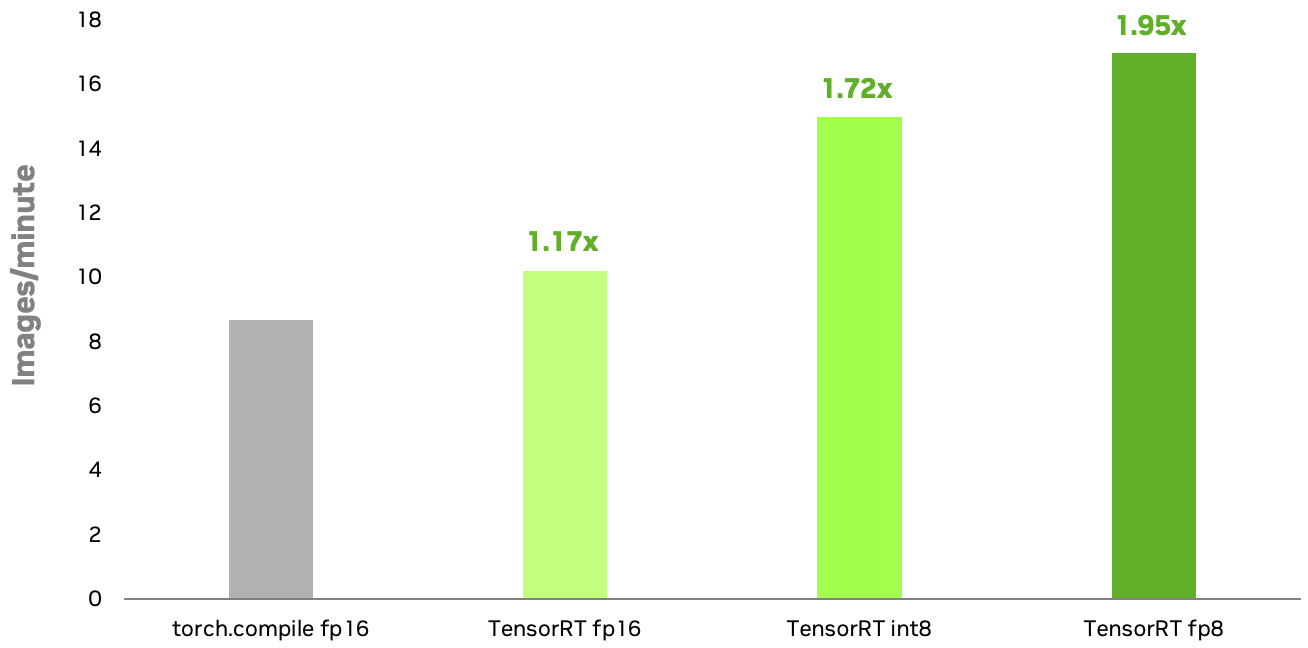
PTQ quantization int8 is slower than fp16 · Issue #1532 · NVIDIA ...
A question about int8 explicit quantization for plugins · Issue #1616 ...
The model after INT8 quantization is slower than before and with higher ...
The impact of multi-batch int8 quantization on engine size and acc ...
OpenVINO INT8 Quantization for YOLO26 Models: A Hands-On Tutorial | by ...
Why model size doesn't decrease after INT8 Quantization using pytorch ...
TensorRT int8 engine (convert from qat onnx using pytorch-quantization ...
Improving INT8 Accuracy Using Quantization Aware Training and the ...
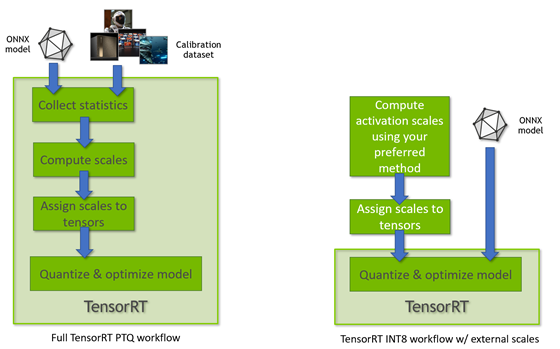
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
The inference speed of the int8 quantization version of SDXL is much ...
How to Convert a Custom-Trained YOLO11 Model to a TensorRT INT8 Engine ...
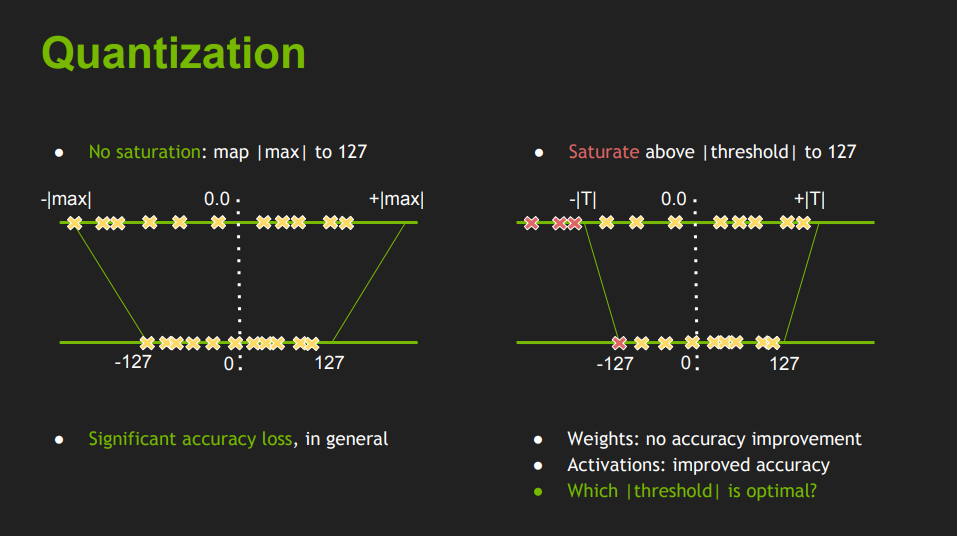
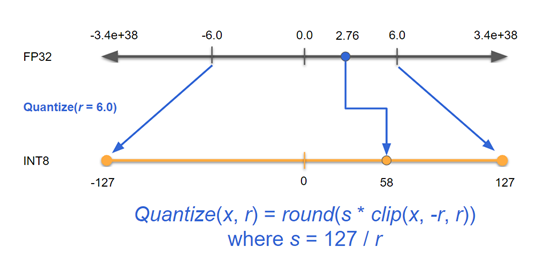
Question about INT8 quantization ranges · Issue #1951 · NVIDIA/TensorRT ...
int8 quantization not work on bert-like embedding model · Issue #4058 ...
TensorRT: Quantization issues with convtranspose3D - TensorRT - NVIDIA ...
Deep Learning Int8 Quantization – PCETSK
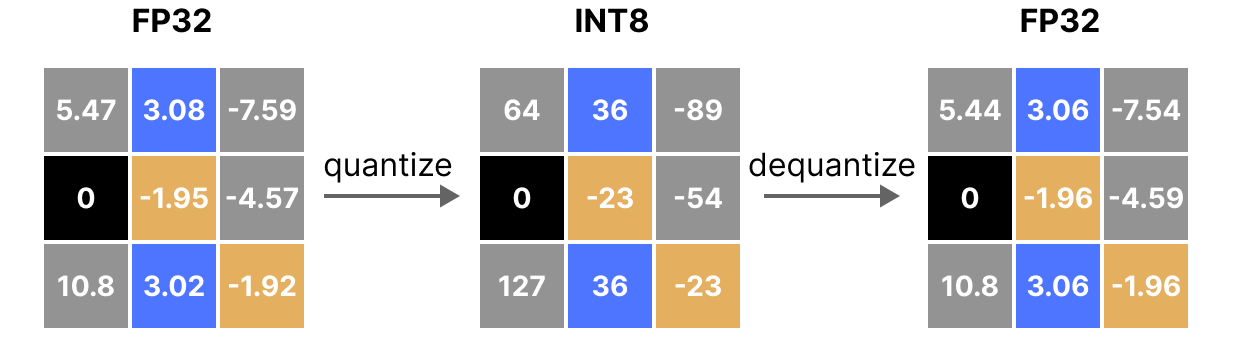
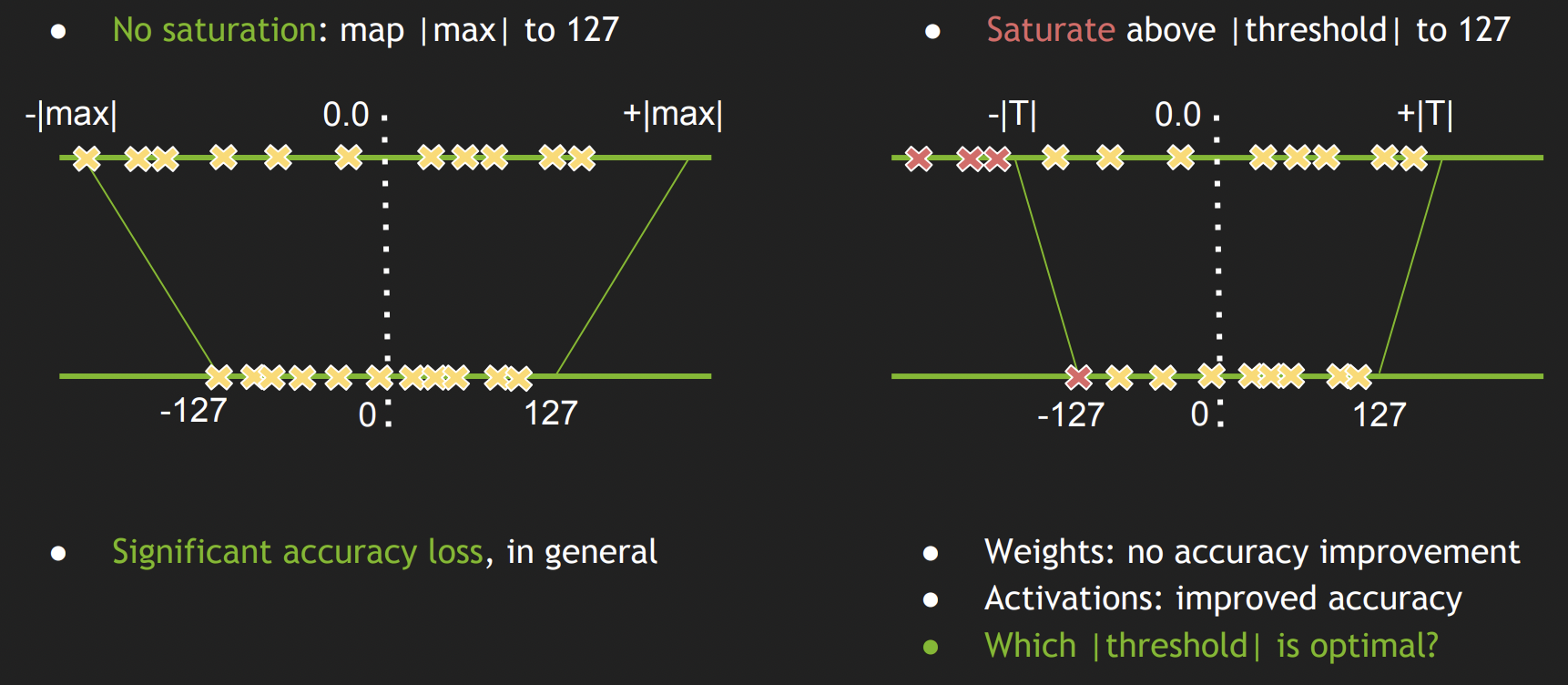
INT8 Quantization Basics | Rand Xie
Fast INT8 Inference for Autonomous Vehicles with TensorRT 3 | NVIDIA ...
Excuse me, does the 3060Ti graphics card support TensorRT int8 ...
NVIDIA TensorRT를 통한 양자화 인식 학습을 사용하여 INT8 추론에 대한 FP32 정확도 달성 - NVIDIA ...
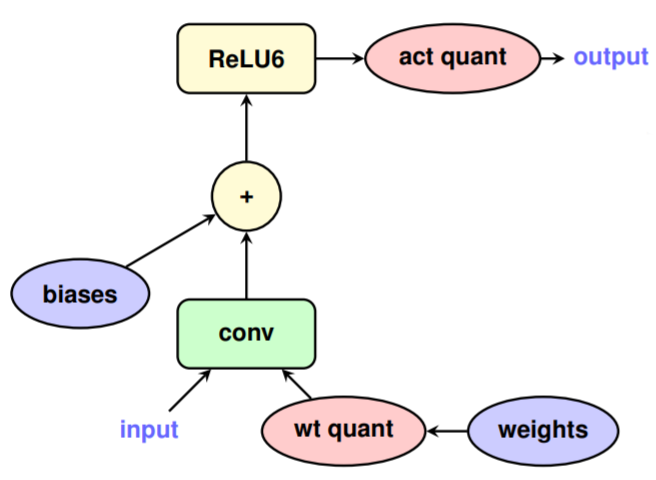
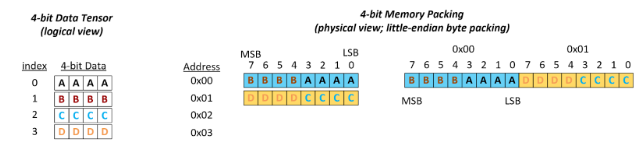
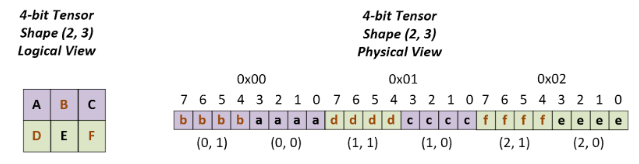
Working with Quantized Types — NVIDIA TensorRT
TensorRT INT8量化原理与实现(非常详细)-CSDN博客
INT8 Inference of Quantization-Aware trained models using ONNX-TensorRT ...
NVIDIA TensorRT Accelerates Stable Diffusion Nearly 2x Faster with 8 ...
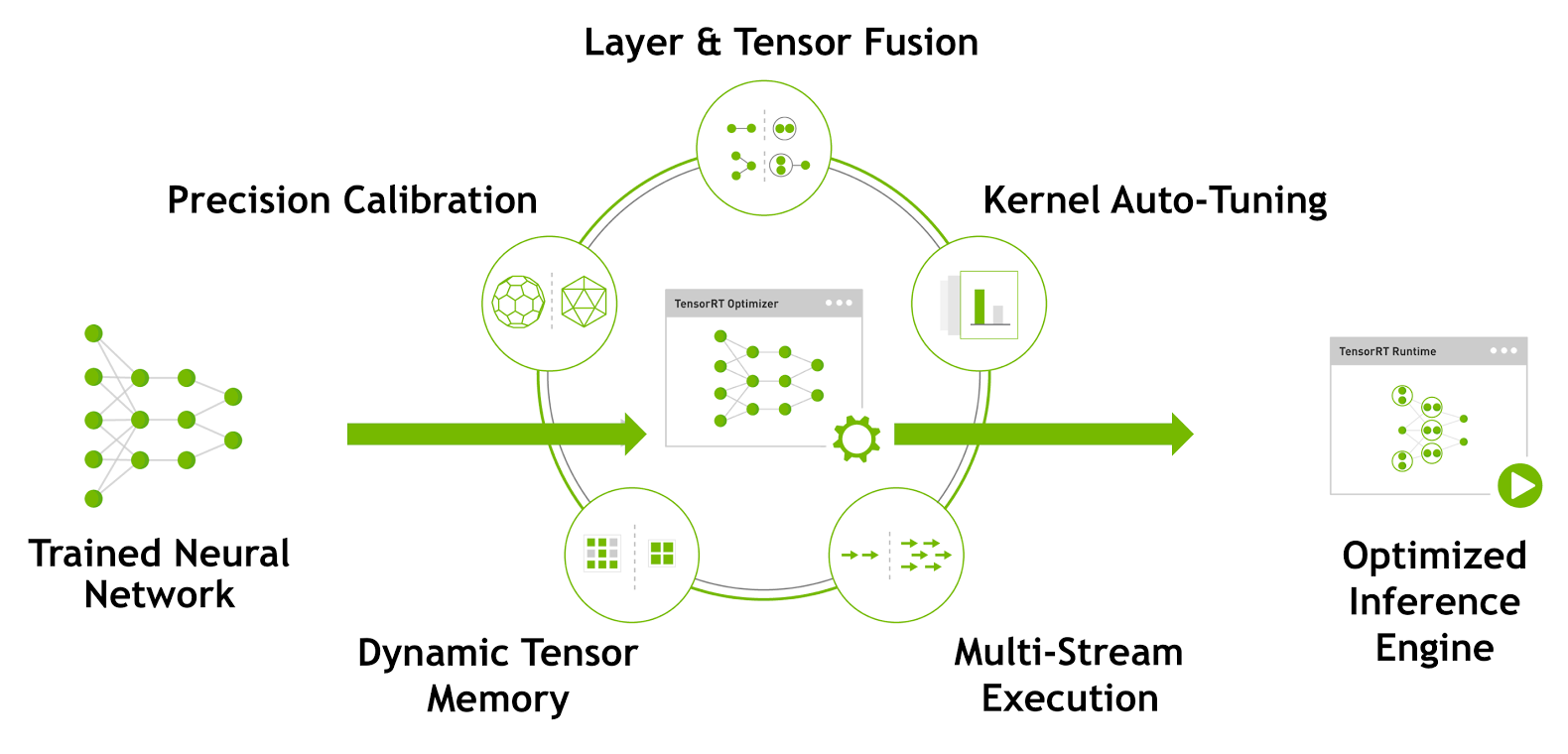
TensorRT SDK | NVIDIA Developer
INT8 quantization? · Issue #5 · talebolano/TensorRT-Scaled-YOLOv4 · GitHub
Manually load int8 weight from QAT model (quantized with pytorch ...
mAP drops a lot when Infer a INT8 quantized ONNX model. · Issue #2237 ...
GitHub - DerryHub/BEVFormer_tensorrt: BEVFormer inference on TensorRT ...
NVIDIA TensorRT 通过 8 位预训练量化将 Stable Diffusion 的速度提升近 2 倍 - NVIDIA 技术博客
Support weight only quantization from bfloat16 to int8? · Issue #110 ...
Understanding int8 vs fp16 Performance Differences with trtexec ...
Failed INT8 quantization. · Issue #1847 · NVIDIA/TensorRT · GitHub
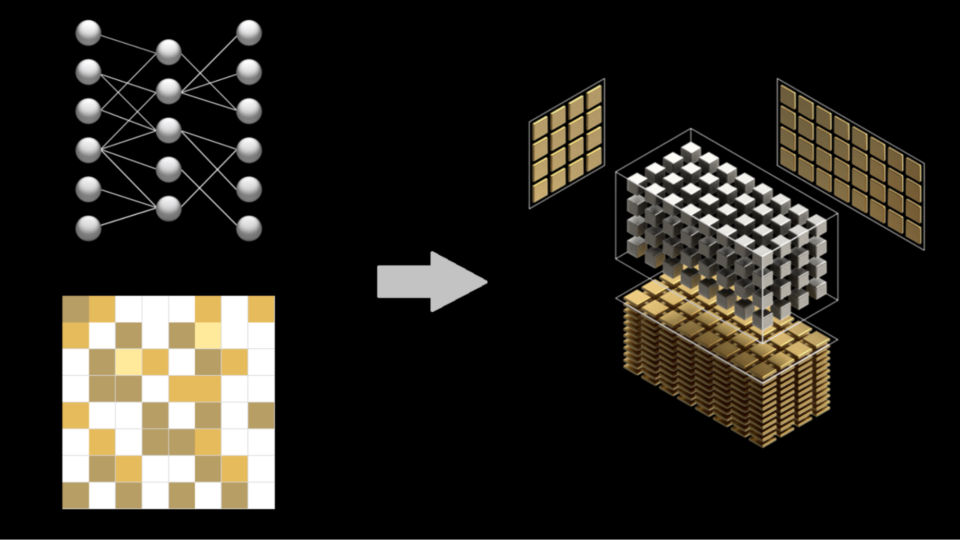
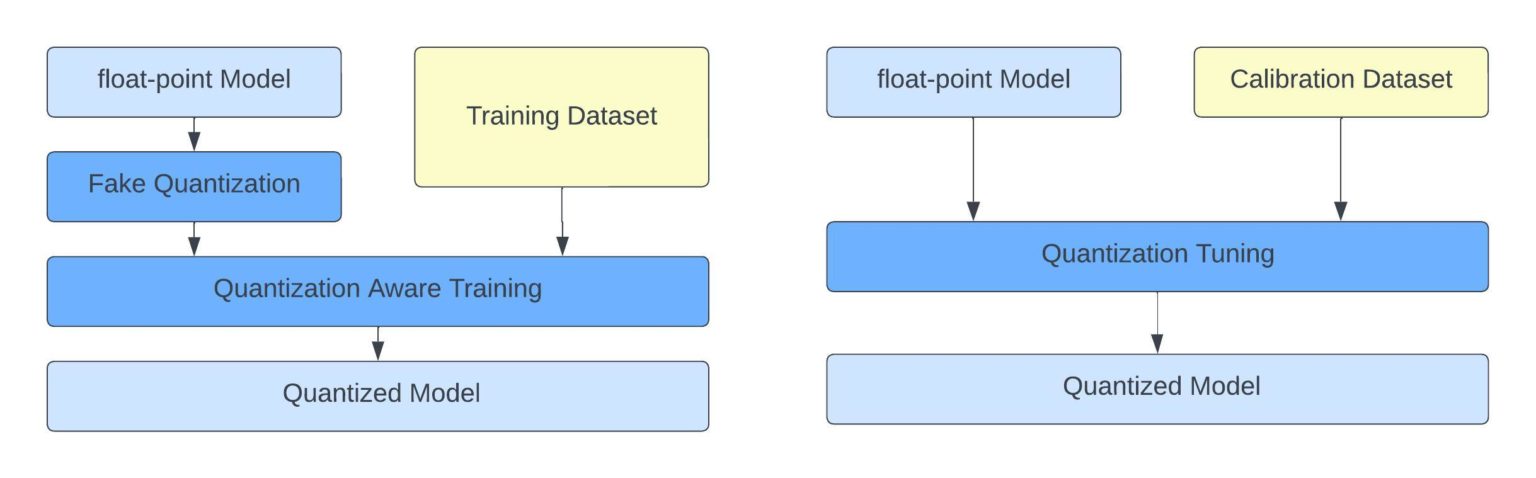
A Visual Guide to Quantization - by Maarten Grootendorst
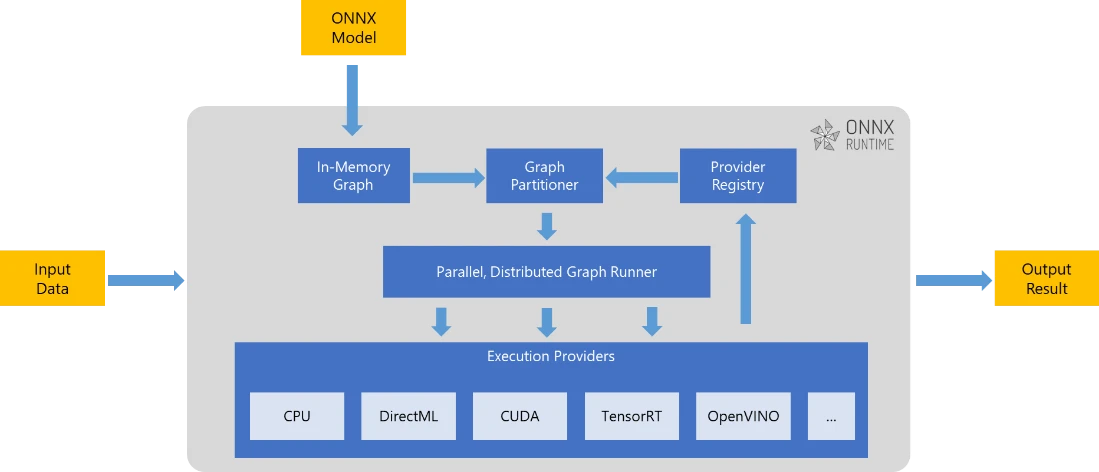
在 NVIDIA GPU 上使用 ONNX Runtime-TensorRT 优化和部署Transformer INT8 - 知乎
Developer Guide :: NVIDIA TensorRT for DRIVE OS
Why does RESIZE and CONCAT cause a lot of latency when using QDQ INT8 ...
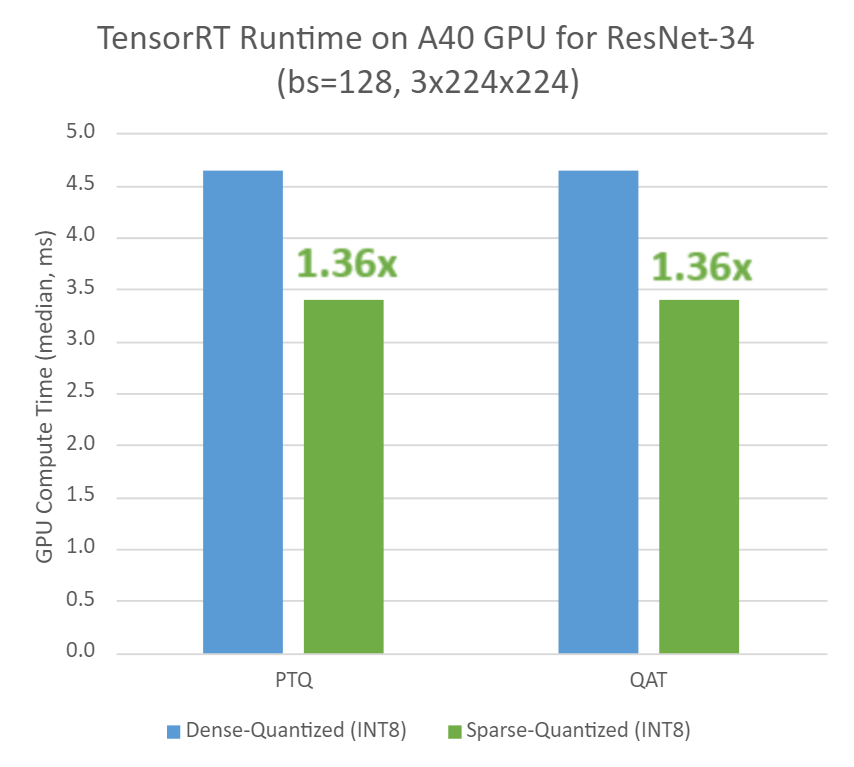
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
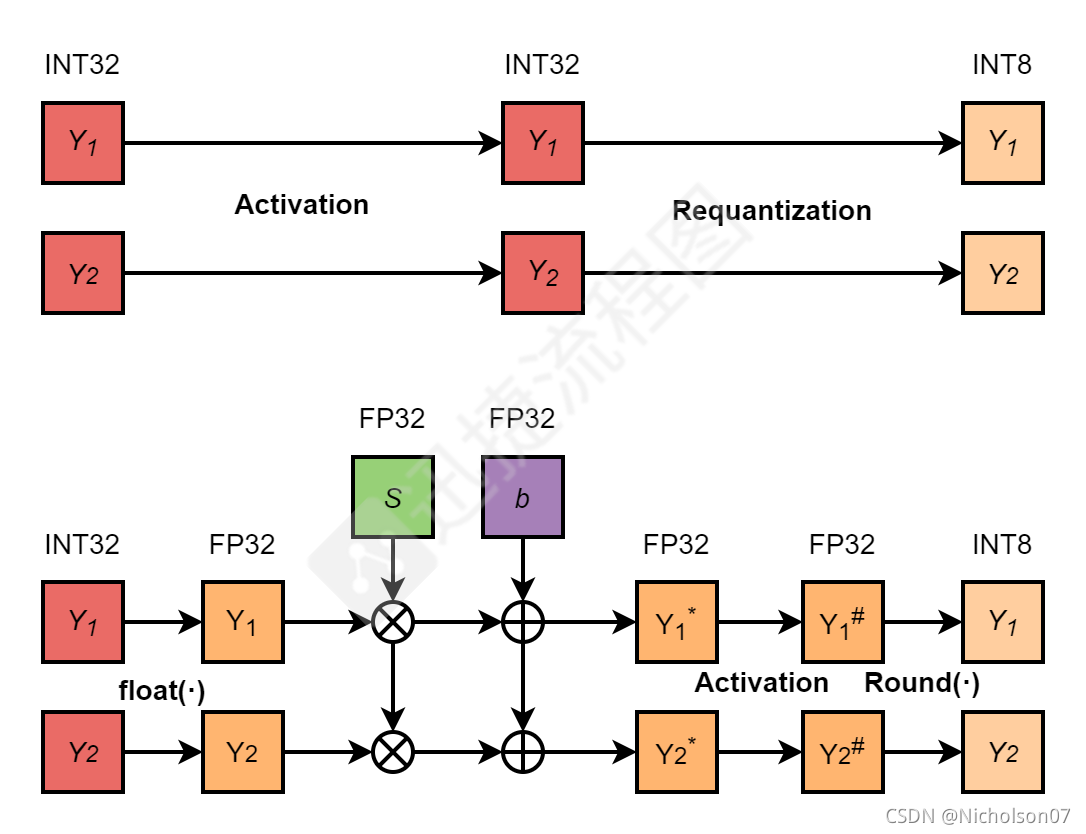
TensorRT:INT8量化加速原理与问题解析_tensorrt int8-CSDN博客
TensorRT——INT8推理 - 渐渐的笔记本 - 博客园
Object Detection on GPUs in 10 Minutes | NVIDIA Technical Blog
Accelerating Quantized Networks with the NVIDIA QAT Toolkit for ...
利用TensorRT实现INT8量化感知训练QAT_tensorrt int8量化-CSDN博客
GitHub - xuanandsix/Tensorrt-int8-quantization-pipline: a simple ...
TensorRT(5)-INT8校准原理 | arleyzhang
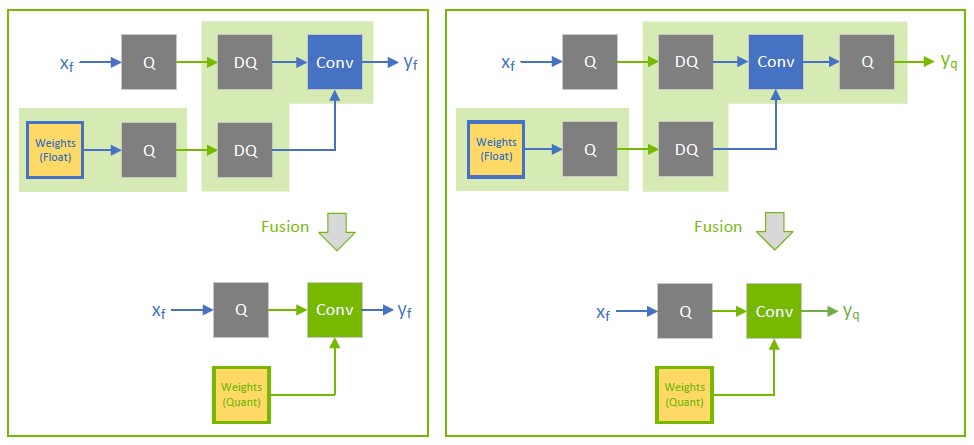
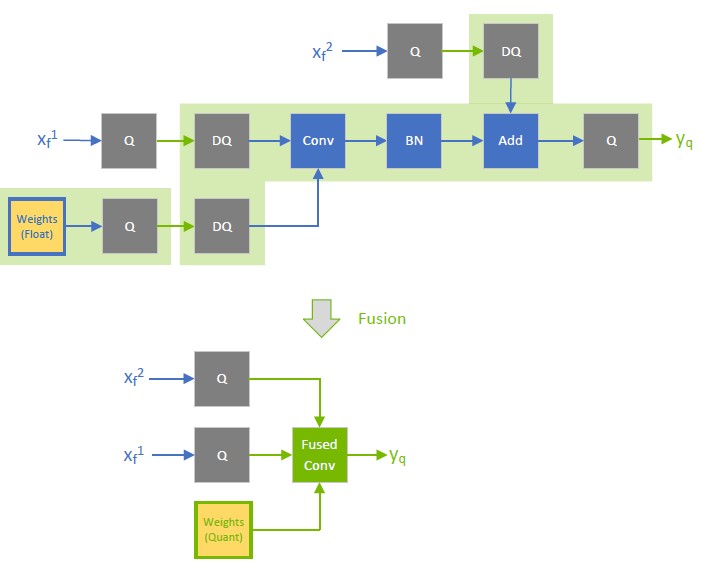
[Int8 Quantization] About node fusion in QAT · Issue #3205 · NVIDIA ...
What is TensorRT? Overview & Use Case
GitHub - lingffff/YOLOv3-TensorRT-INT8-KCF: YOLOv3-TensorRT-INT8-KCF is ...
[Hugging Face transformer models + pytorch_quantization] PTQ ...
[int8 quantization] rules for correct Q/DQ node placement with add ...
7. 如何使用TensorRT中的INT8 - 知乎
【yolov8目标检测部署】TensorRT int8量化_yolov8 int8量化-CSDN博客
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
tensorrt-int8量化介绍_tensorrt int8-CSDN博客
神经网络INT8量化~部署_tensorrt树莓派-CSDN博客
TensorRT-8量化分析 - 吴建明wujianming - 博客园
Высокопроизводительный инференс глубоких сетей на GPU с помощью ...
CUDA与TensorRT(7)之TensorRT INT8加速_cuda int8-CSDN博客
从TensorRT看INT8量化原理 - nanmi - 博客园
TensorRT模型,INT8量化Python实践教程 - 智源社区